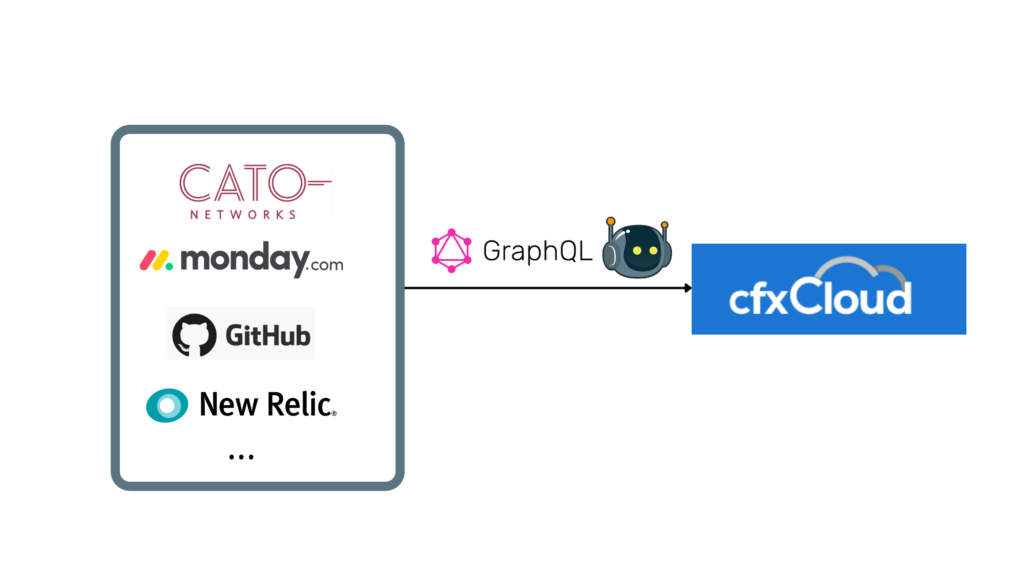
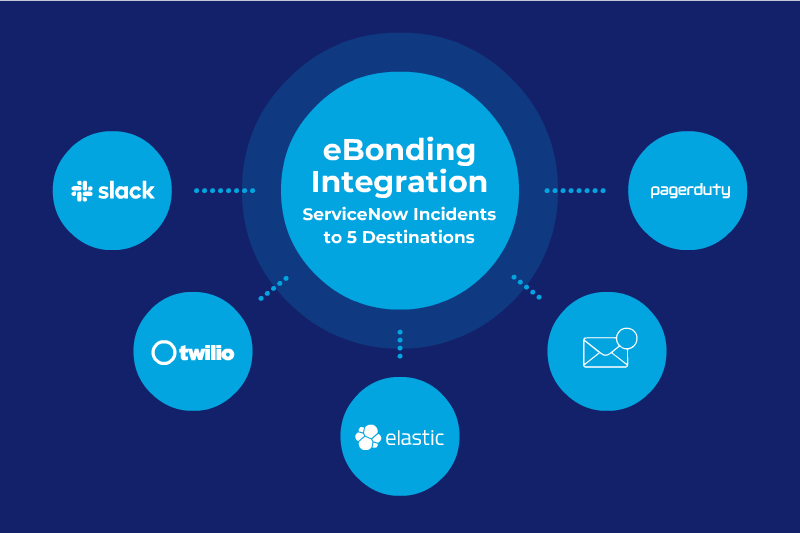
Why Data Silos Exist and How they Hurt an Organization
Enterprises today want real-time business insights to make decisions that improve operational efficiency and customer engagement and present newer revenue opportunities. However, the promise of the data-driven business falls short due to gaps in data management.
These gaps exist because data in the modern enterprise doesn’t exist only behind firewalls and within organizational premises. The data is globally distributed in data warehouses, databases, on-premises, partners, public/social networks, edge and multiple clouds.
These data silos exist because of the exponential growth of data over the last decade through edge computing, artificial intelligence, hybrid cloud and the internet of things. Data today exists in organizations in various sources including spreadsheets, core financial systems, cloud, CRM systems and more.
Data silos cost dearly to organizations in the form of inaccurate and non-standardized data that cannot be leveraged to build insights and make decisions. Data silos slow down operations, limit collaboration and communication, eat expensive storage space, reduce efficiency and reduce data quality.
Data silos lead to security and privacy risks when organizations don’t have appropriate data access controls and compliance processes.
It’s next to impossible for key stakeholders to view at a glance the state of their organization when data is fragmented. Inconsistent data leads to financial and reputational risks. And finally, storing data in silos negates the purpose.
Data silos cut out any opportunity for innovation or usefulness from data. In short, they are expensive.
What is a Data Fabric?
According to Gartner, Data Fabric is one of the key trends for this year. Gartner defines Data Fabric as “enabling frictionless access and sharing of data in a distributed data environment. It enables a single and consistent data management framework, which allows seamless data access and processing by design across otherwise siloed storage.”
In essence, data fabric facilitates the integration of disparate data pipelines and cloud environments using intelligent, automated systems. Data Fabric allows enterprises to not only unify data but also embed governance, solidify security and privacy and improve data accessibility for everyone across the enterprise.
Traditionally, organizations have separate platforms to address LOBs, such as a platform for supply chain management, another to house customer data and one for HR-related information. Data fabric weaves a live fabric symbolically out of threads of disparate data, enriched by the underlying metadata to visualize this holistic data and find patterns in seemingly siloed places.
It saves organizations from the continuous and increasing costs of merging and redeploying siloes with new data, essentially inventing the same challenges repeatedly. The modern enterprise uses data in motion, continually identifying and connecting data sources to discover unique, business-relevant patterns that augment and improve decision making.
How DataFabric Democratizes Data
Gartner notes, “Through 2025, 80% of organizations seeking to scale digital business will fail because they do not take a modern approach to data and analytics governance.”
Data democratization means providing access to data to non-technical users of IT infrastructure so that decision-making can happen at all hierarchical levels uniformly. Data democratization pacifies data ownership, warranting not only a technological but a cultural shift in how data is managed and leveraged.
Data democratization happens through Data Fabric and leads to the following:
- Data accessibility beyond technical resources – Data democratization allows non-technical professionals to access and make sense of data and empowers them to partake in decision making. It also promotes transparency and accountability.
- Efficient business decision-making – With exposure to data from across the organization, decision makers can spot consumer trends and market needs. Since data is accessible to the entire organization, employees at all levels can leverage it and work toward a shared goal faster.
- High productivity – According to Gartner, “by 2024, organizations that utilize active metadata to enrich and deliver a dynamic data fabric will reduce time to integrated data delivery by 50% and improve the productivity of data teams by 20%”. Data Fabric reduces internal processing time and diverts data teams to strategic, high-value tasks.
- Better support for advanced analytics – Data analysts and scientists traditionally view data lakes as their field of operation. This is a challenge when we consider the amount of data replication, expensive egress costs and the assumption that all enterprise-wide data can reside in one lake. Data fabric solves this challenge by seamlessly connecting data sources to consuming applications and allowing data scientists and analysts to work with a variety of models and tools as they fit their expertise. Resulting, professionals focus less on collecting, preparing and transforming data for use and more on leveraging the data for rich insights.
- Seamless data integration – Data Fabric can offer a transparent, enterprise-wide view of real-time data across on-premises and on-cloud locations without needing to replicate anything. This allows for semantic consistency so that individuals across borders can use BI tools to query information.
Balancing Easy Access to Data with Cost and Compliance
As data governance and security are critical to data privacy, they can be stepping stones and not roadblocks to data democratization. Universal access to data can unlock potential in an organization.
Regulations are increasing globally, and consumers are more aware than ever of the repercussions of poor handling of their personal data. Therefore, the data fabric must have compliance and data management lineage capabilities built into it.
The chosen platform takes care of access controls and handles regional compliance needs. As today’s modern enterprise is global, the platform ideally handles any regional compliances an organization must abide by.
Regulatory privacy and security can thus be balanced with easy and global access to organizational data for efficient decision making.
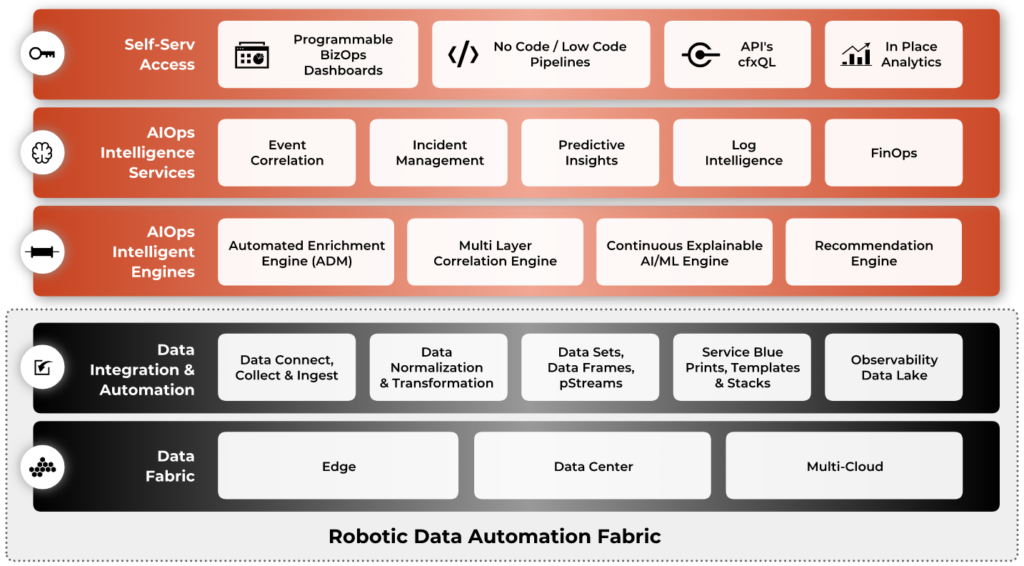
CloudFabrix implementation of Data Fabric technology through its Robotic Data Automation Fabric comprises of multiple layers providing a comprehensive solution for digital enterprises
- Data Integration layer across disparate sources and sinks, formats and data types,
- Data Automation layer shaping, enriching and contextualizing the data stream, running AI/ML and analytics pipelines to derive actionable intelligence and routing to multiple sources and sinks.
- Data intelligence layer builds services using these pipelines for each supported use case, e.g. Log Intelligence for managing log data, Customer 360, AIOps etc. Finally,
- Data access layer provides a self-service layer for different personas to gain insights into the data pipelines –
- browser based Digital playground, on demand dashboards and reports for citizen developers,
- RDAF Serverless Pipeline Functions is a powerful approach to bring data using REST API’s and CLI’s to the low code pipelines for Data Scientists and Analysts and finally
- Data studio for IT and DevSecOps domain users.
RDAF platform is consumed as cfxCloud and cfxEdge which run as microservices in AWS cloud or hybrid data centers.
To Learn more here.