Artificial Intelligence for ITOps (AIOps) can help accelerate incident response with all the incident context, impact assessment, triage data and collaboration & automation tools at one place. More specifically AIOps can help automate root causing analysis, enrich the incident with full-stack for impact analysis, present incident relevant Observability data (metrics, logs and traces) in a single pane triage dashboard, and provide built-in diagnostic commands and workflow or runbook automation leveraging integrations with RPA tools.
AIOps: What is Incident Response:
It is a standard practice in IT organizations to capture IT operational problems or issues as incidents in an IT Service Management (ITSM) system like ServiceNow, BMC Remedy, PagerDuty, Jira ServiceDesk etc. A Majority of these incidents are created directly by monitoring tools or by an AIOps platform which takes events and alerts from monitoring tools and creates actionable incidents by performing event correlation and alert noise reduction. IT users and stakeholders (like LoB users, managed service customers etc.) can also report IT problems (via phone or portal), which get recorded as Incidents in the ITSM system.
In either case, the intent of the Incident is to capture all relevant data regarding the problem, which typically includes problem description, severity, impacted assets/services, incident reporter, etc. Once the Incident is created, a Service Desk operator is assigned to triage, diagnose and resolve the problem.
A service desk personnel helps to understand where these teams and tools fit in the IT organization. Typically, ITSM systems are owned by Enterprise Tools team, IT Operations team or Network/Security Operations Center (NOC/SOC) or IT Service Desk. NOC/SOC or Service Desk, may host dedicated personnel, whose job is to triage, diagnose and quickly resolve incidents. If any incident is out of their purview, it is escalated to other personnel with specialized skills. These teams are setup to operate in a tiered fashion, and are colloquially referred to as L1, L2 or L3 engineers, i.e Level-1, Level-2 and Level-3 (or in some cases Tier-1/Tier-2/Tier-3), with L3 holding the most specialized skill-set.
Think of L1/Tier-1 operators as the first respondents that can most often perform a lot of first aid/diagnosis type of work and quickly repair or resolve, when provided with the right set of tools. However, problems that cannot be solved by L1/L2 get escalated to L3 or even application teams. It is generally economical and SLA-friendly for the IT organization if L1/L2 can diagnose and resolve most of the problems without having to involve more L3 personnel, whose specialized skills, time and resources are scarce, and hence also turns out expensive for IT organizations.
How can IT organizations enable their L1/L2 engineers to perform their job effectively, handle more incidents, reduce the number of escalations and reduce SLA breaches?
For this, we need to understand what are some of the challenges faced by L1/L2 engineers that result in escalations?
Challenges in Incident Response:
Incidents capture problems arising in IT services, which can be quite vast and complex in a typical large enterprise. An IT service can span multiple applications, infrastructure devices and can use a range of shared services and cloud/saas services. Typically such environments can be hybrid (on-prem + cloud) in nature and filled with legacy and modern infrastructure.
Following are few mundane (read as laborious, repetitive and error-prone) activities and challenges that L1/L2 operators have to perform and undergo performing incident response on a day-to-day basis
- Triage and prioritize incidents
- Identify services or assets impacted
- Issue ping, trace route or other such simple sanity checks
- Log into multiple monitoring tools and check metric values
- In some cases remote login to a device to check status
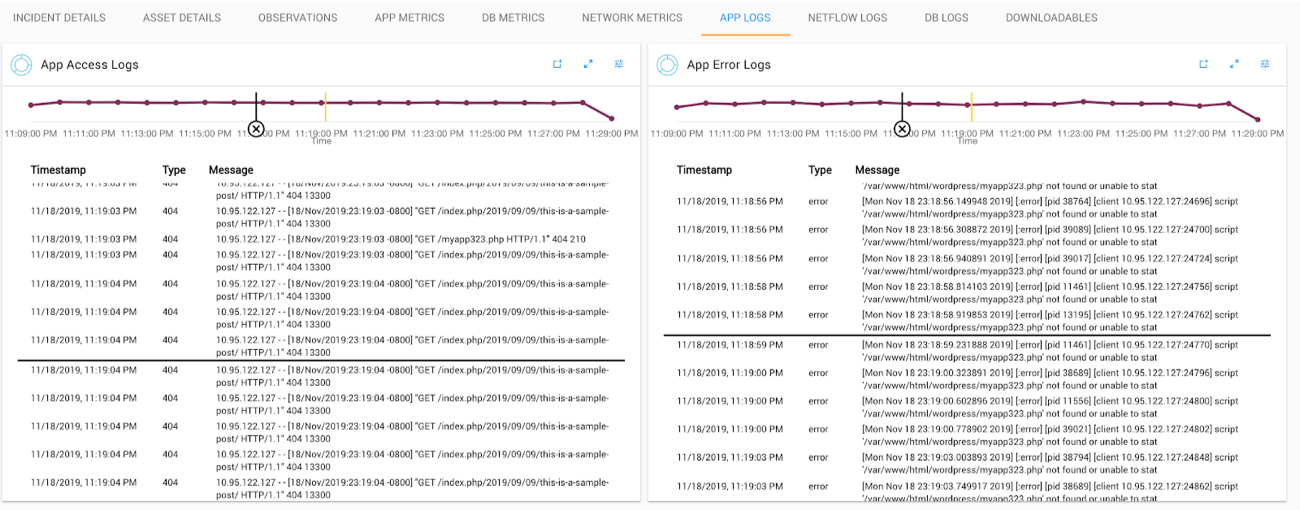
- Check log files on multiple systems to detect any errors
- Issue some low to medium-risk commands that change system state (ex: service restart, add stateless VM/container etc.)
- If the issue is likely due to a problem from vendor, create & track issue with customer support case#
- Look for any known or published vulnerabilities
- Verify if there are any known defects or bugs that report the same issue
- Update Incident notes with findings from above activities
- ‘Resolve’ the incident if successful resolution is determined or escalate to Tier-3
- Tier-3 may perform deeper analysis and coordinate with multiple teams and also call for a war-room to get to the bottom of the problem.
Most of the above L1/L2 activities are often repetitive, time-taking and error-prone, but also low-risk and ripe for improvement using modern solutions leveraging AIOps and RPA technologies.
How can service desk personnel accelerate incident diagnosis or resolution process? How can such detours be minimized and have all the essential incident-relevant knowledge at one place?
Common Incident Response Characteristics in Cisco Environments
When it comes to IT infrastructure, Cisco is the world-wide market leader in Switching, Routing and Wireless segments and 3rd in Server/Computing segment (as of Q42019). Rightly so, every environment that we run into has a lot of Cisco gear; even to the extent that some large accounts are entirely Cisco shops, having hundreds and thousands of Cisco devices. Such Cisco environments have a few common characteristics when it comes to IT incidents
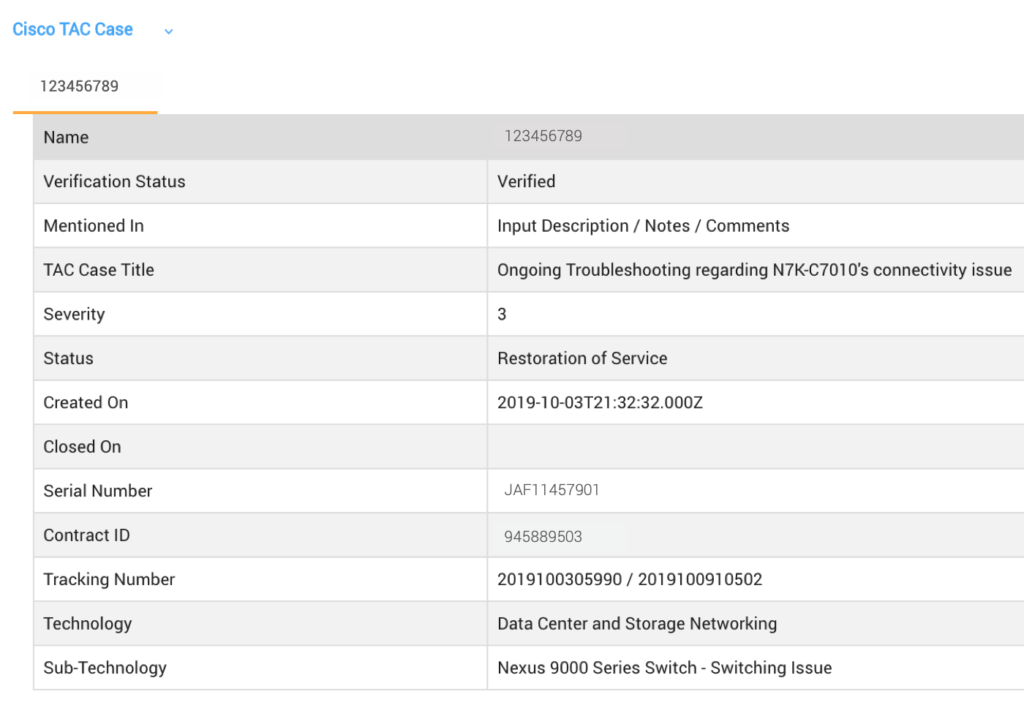
- TAC Cases: Customer opens support tickets with Cisco Technical Assistance Center (TAC) requesting customer support
- Field Notices: Field notices require an upgrade, workaround, or other customer action.
- Security Advisories (PSIRT): A known or published security vulnerability that can impact multiple products, often requiring attention and workaround or fix
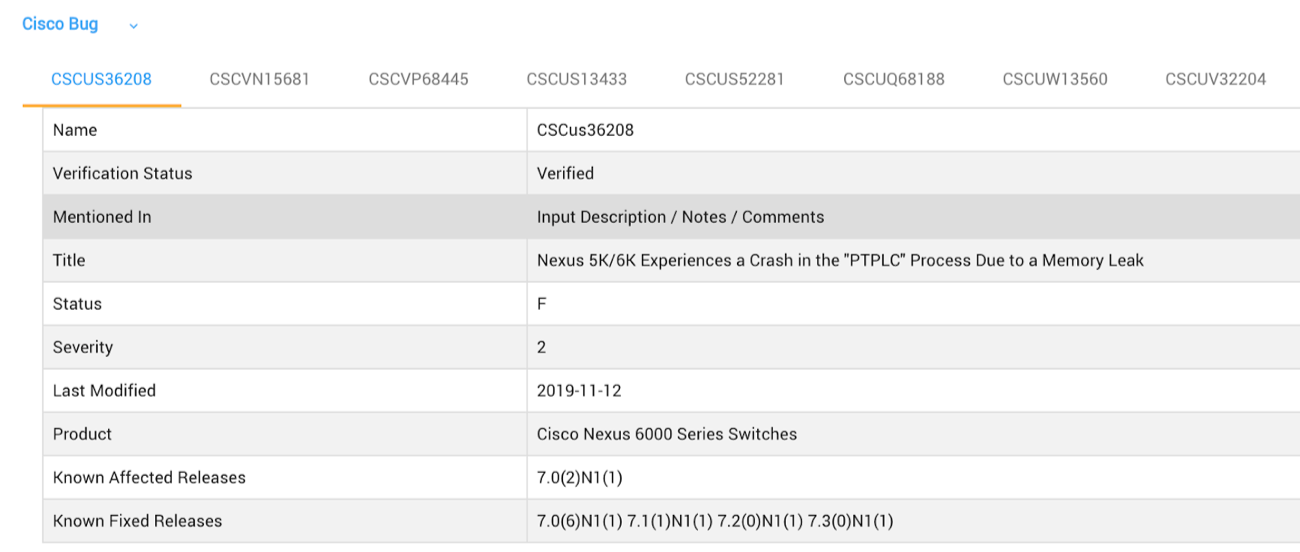
- Bugs or Defects: Known defects in hardware or software that impact or limit expected functionality. Often has workaround
- EoL/EoS: End of life policy announcements that identify key lifecycle events of Cisco assets, including hardware and software
- Supportability: Cisco hardware and software assets that are generally covered under a support contract. Cisco Support APIs provide this information for partners and Smart Net Total Care (SNTC) customers.
IT service desk personnel often have to work with two or more of the above aspects to effectively handle IT operational issues in Cisco environments.
Manual operations of such activities involves frequent interactions with external systems and vendor portals, including login to support portal, search for support cases, review status and activity feed, correlate with local incidents, find latest status of defects, explore vulnerability details etc. After such detours to vendor portals, update Incident notes in local ITSM system to keep a record of happenings.
How can service desk personnel accelerate incident diagnosis or resolution process? How can such detours be minimized and have all the essential incident-relevant knowledge at one place?
This is precisely what CloudFabrix AIOps solution is designed to address, with its latest Knowledge Mining feature.
AIOps Solution: To Accelerate Incident Response
CloudFabrix AIOps solution which is a modern digital collaborative war room that enables faster incident diagnosis and resolution of alerts or incidents. AIOps solution provides context-aware metrics and logs, automated knowledge mining and asset intelligence, security insights and diagnostic tools to enable rapid incident response.
AIOps solution is turning out to be a valuable tool for IT operations teams and bringing efficiency in the way the handle and respond to incidents.
Key features include:
- Dynamic ingestion of incidents from ITSM (Ex: ServiceNow)
- Generating a dynamic and intuitive web page for every incident
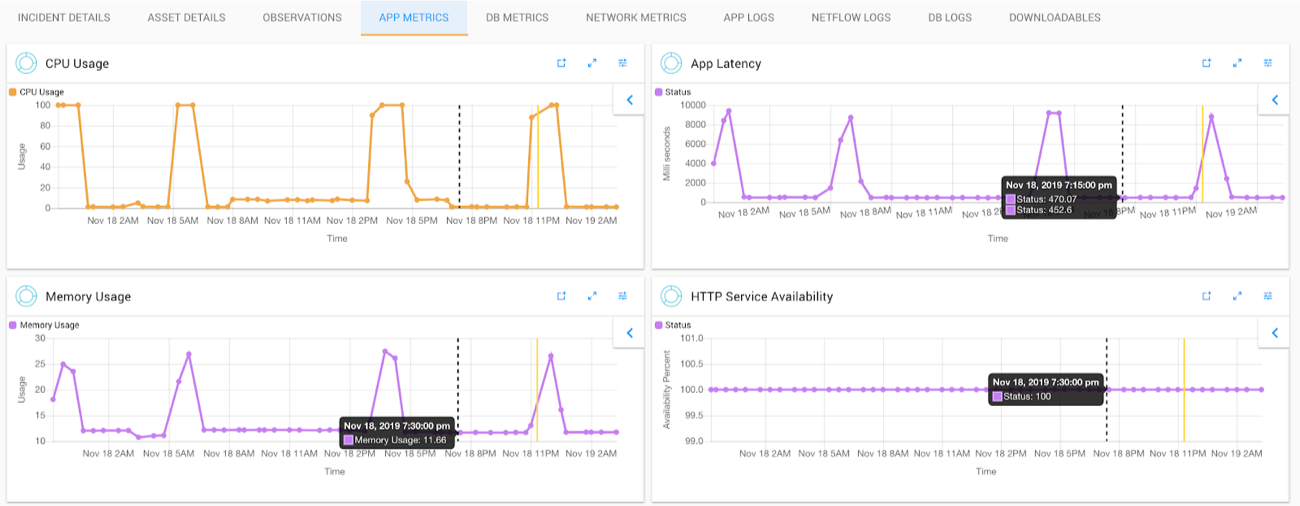
- Retrieving incident relevant metrics & logs automatically
- Providing time-sync and time-markers to compare metric and logs across multiple assets
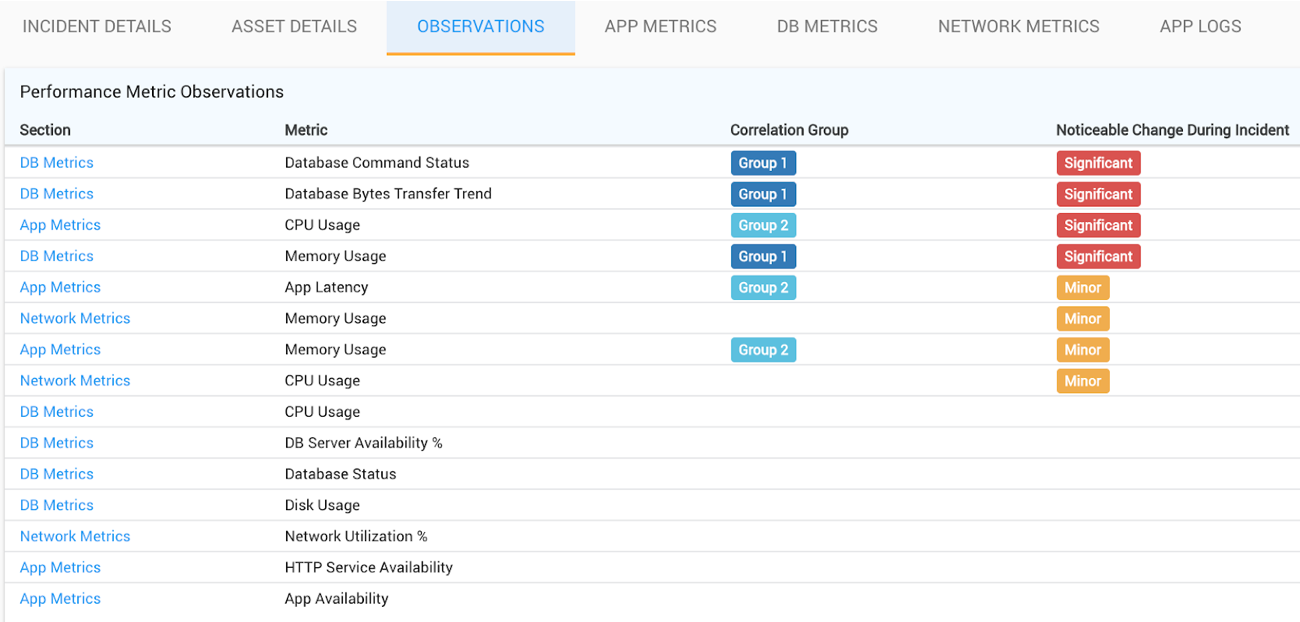
- Providing key observations highlighting anomalies, correlated metrics
- Enabling faster investigation and root cause identification by highlighting metrics that have noticeable changes
- Providing diagnostic tools and external workflow invocations (ex: RPA tools/runbooks etc.) for low/medium risk task automation
- Knowledge mining (more below)
- Additional Resources, available for download and offline reporting
AIOps Knowledge Mining
Generic/Broadly Applicable
- Similar incidents: show other related or similar incidents, based on machine learning k-means clustering and euclidean distance
- Suggested next steps: suggests next steps based on empirical learning from historical incidents (ex: which user to assign, action: resolve/hold/close/cancel)
Key Benefits in Cisco Environments
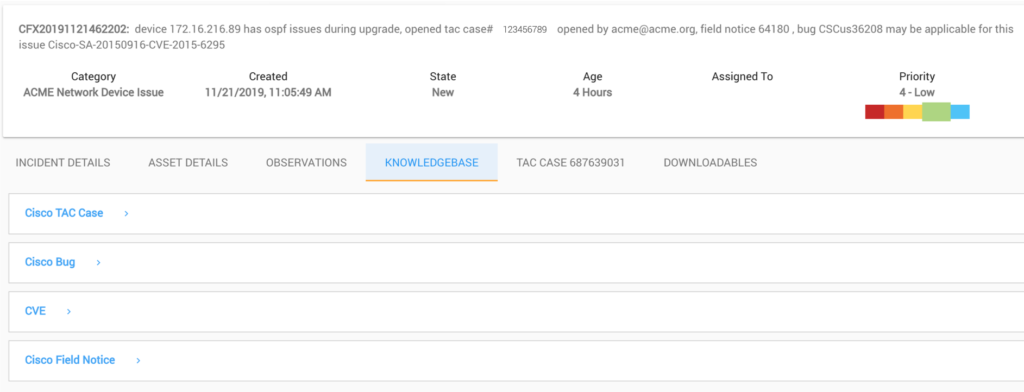
- Cisco TAC Cases Trail: Automatically retrieves all case details, including latest status, case activity updates and Email trail
- Cisco Field Notices: Provides details about associated field notice, including a clickable URL, title, verification status etc.
- Cisco CVEs: Name, Title, Verification status, Details and clickable-URL to Common Vulnerabilities and Exposures (CVE)
- Cisco Bugs/Defects: Retrieve key bug/defect details, including related bugs. Details include defect status, severity, product, affected versions/releases, known fixed versions/releases
- Cisco EoS/EoL: Shows key lifecycle risks associated with impacted devices, including including end-of-support and end-of-life events.
AIOps Incident Response Typical Benefits
AIOps solution is turning out to be a valuable tool for IT operations teams and bringing efficiency in the way the handle and respond to incidents. Few key benefits realized include:
- Upto 50% reduction in the mean time to detect/resolve (MTTD/MTTR)
- Upto 40% incidents auto diagnosed or resolved
- 70% cost savings due to reduced escalations and call-outs
- 100% SLA compliance enabled by instant access to relevant operational data and automation
Next Steps
Our solution can be deployed on-premises or leveraged as a SaaS solution, which can easily connect to all your on-premise data sources using featured integrations and open APIs. Please feel free to reach out to us if you are interested to learn more or try out our cloud hosted SaaS version for free Sign up now.



