This is the first article in our AIOps Feature Scape series. The idea behind the Feature Scape series is to talk about key operational tasks and processes in AIOps, and how CloudFabrix Data-Centric AIOps platform features help implement such tasks. Look for more such articles over the next few weeks.
This Feature Scape article covers Data Integration, which is typically the first step in bringing data into the AIOps platform, and covers how the Insane New CloudFabrix Robotic Data Automation Fabric (RDAF) accelerates data integrations with various IT and cloud data sources/targets.
Context
AIOps platforms need to process vast amounts of data in order to learn from data, eliminate noise, identify the root cause and drive towards autonomous and predictive IT operations. Modern IT environments are expanding to datacenter, multi-cloud, edge, and hybrid environments – comprising a mix of modern and legacy tools that have many different data and API characteristics.
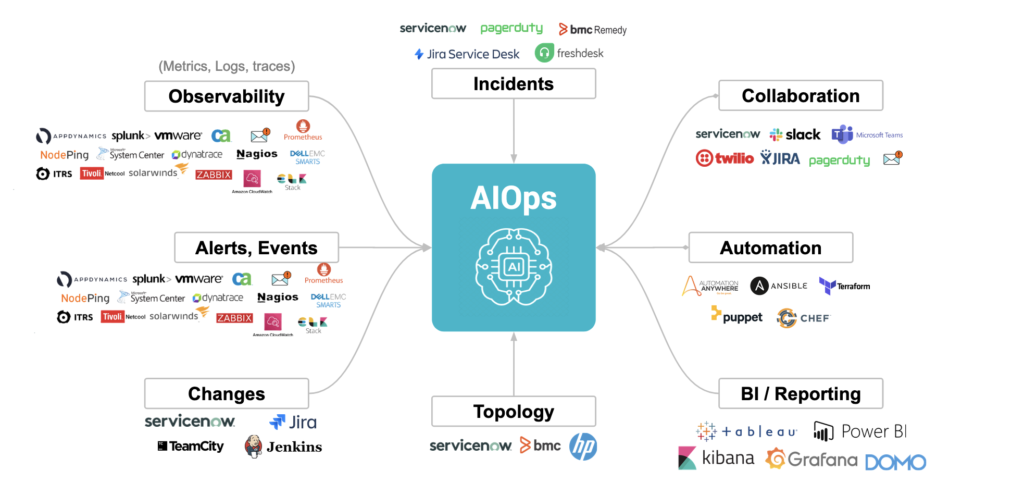
Let us understand what are some of the key challenges in data preparation & data integration activities when implementing AIOps projects.
- Different data formats (text/binary/json/XML/CSV), data delivery modes (streaming, batch, bulk, notifications), programmatic interfaces (APIs/Webhooks/Queries/CLIs)
- Complex data preparation activities involving integrity checks, cleaning, transforming, and shaping the data (aggregating/filtering/sorting)
- Raw data often lacks application or service context, requiring real-time data enrichment and bringing in context from external systems.
- Implementing data workflows requires a specialized programming/data science skill set
- Changes in source or destination systems require rewriting/updating connectors
Traditional/Comparative Approaches
Most AIOps platforms would integrate with featured tools without any problems. A real issue arises when you have custom data formats or legacy tools.
To address these scenarios:
- Software vendors provide an API, and the customer needs to send data to the API
- Customers need to have programming skills (ex: Javascript/Python) to customize data payload
- Limited data customization for featured integrations (ex: just limited to adding key-value pairs)
- Dependency on professional services to implement custom data integrations
CloudFabrix Feature for Data Integration: Robotic Data Automation Fabric (RDAF)
Our approach for insanely fast and customizable data integration is to use low-code/no-code data observability pipelines using RDAF, which is CloudFabrix’s data operations platform that serves as a foundation for AIOps workflows.
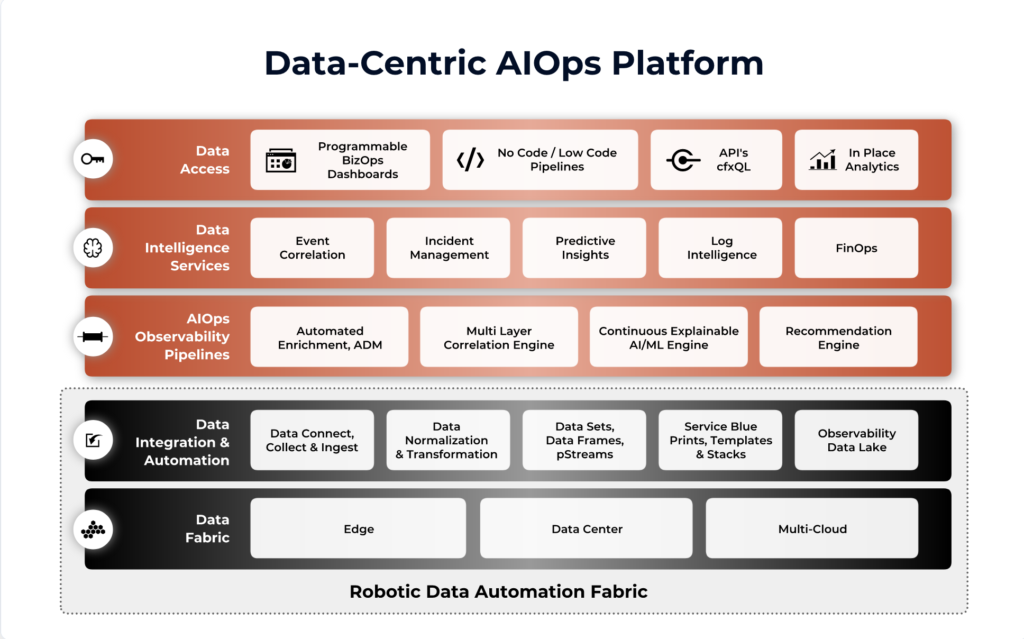
Fig: CloudFabrix AIOps Key Components
How RDAF enables and accelerates Data Integration
RDAF enables data integrations using low-code/no-code pipelines, featured extensions, and numerous data bots.
Key concepts/terminology: Think of a bot as a reusable code block or function that can perform an automated data task over and over again. For example, post-message-to-channel is a bot that posts input data frame to a specified Slack channel, and @kinesis:write-stream is another stream-processing bot that can write input stream to AWS Kinesis. One or more such related bots are packaged together as an Extension. For example, see Dynatrace extension and it has 11 bots
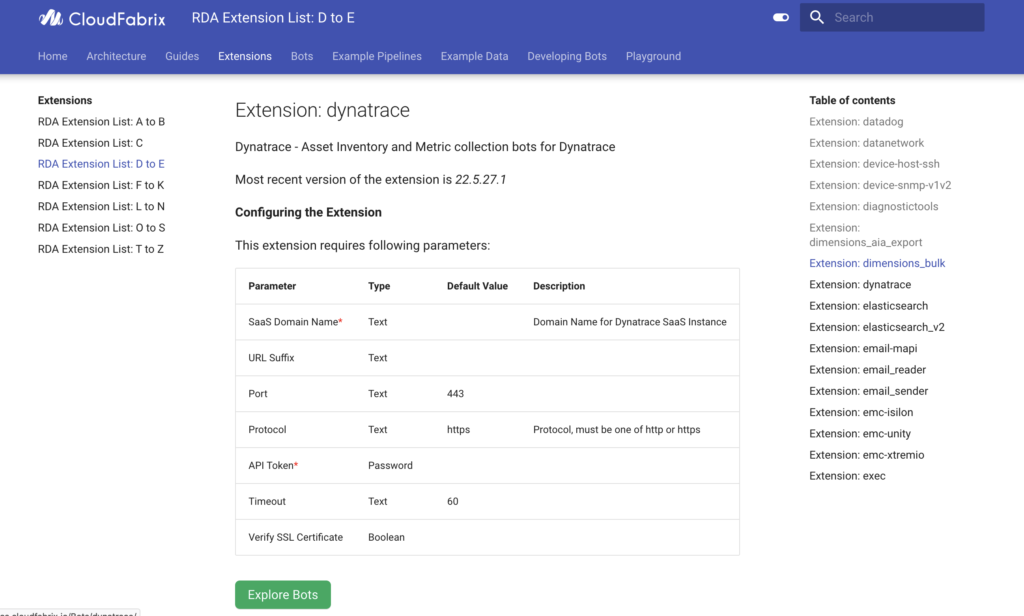
Bots can be sequenced together to execute and pass data from one bot to another, forming a directed acyclic graph (DAG) or a pipeline (aka workflow). The key here is that these workflows are implemented with a low-code/no-code declarative model, using YAML-like syntax. Comprehensive and real-world integration scenarios can be very easily developed by citizen developers, business technologists, and DevOps/SRE personnel, without really having software programming or data science expertise.
Following is an example of a Data Integration pipeline, that listens for Cisco ThousandEyes alerts on a Webhook and streams these alerts to our AIOps platform, by applying some filters on eventType
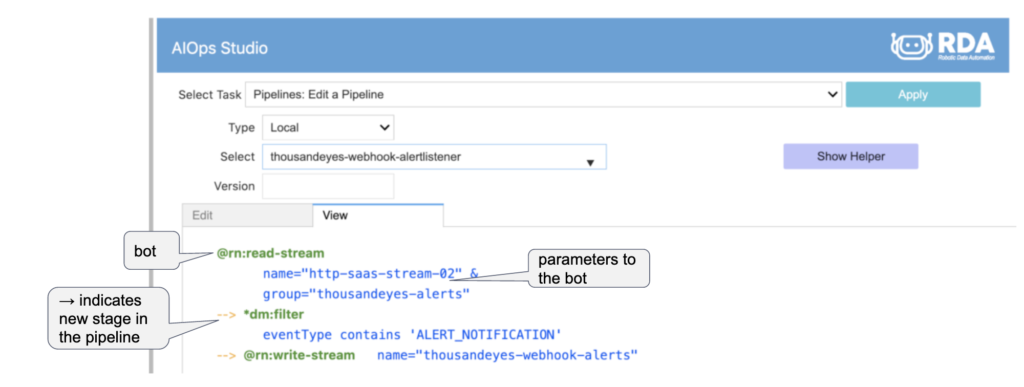
If you are wondering, what is this interface? This is our AIOps Studio, Jupyter Notebook-style visual workbench for authoring, testing, inspecting, and publishing pipelines. Every AIOps installation comes with this Studio. Think of pipelines as sequencing of bots and each bot take parameters, some mandatory, some optional (similar to Linux command line flags). Initially, you may find it difficult to pick the right bot for your task, but trust me, once you know which bot to use, you will start cranking out pipelines in no time. Curious to know more? explore some more example pipelines. We also have a no-code visual pipeline designer that allows for a drag-n-drop approach to building pipelines.
Bots and pipelines execute in data processing nodes called Workers, which are containerized software modules that can be installed anywhere, using docker-compose or Kubernetes helm charts. Workers form the core of the data plane, and every AIOps installation gets one or more Workers for data processing and pipeline execution. Workers can be deployed anywhere, for example, in remote branch sites, datacenters, aggregate sites, or your cloud VPCs, and essentially extend the fabric and allow you to ingest and integrate with local data sources without having to punch firewall holes in your corporate network.
All the worker nodes communicate over a secure, high-performance, and low-latency message bus that forms the core of the data fabric for AIOps. We use NATS.io as our data fabric and we made some customizations to suit our needs. NATS.io is being used by some renowned organizations like Tesla, Walmart, Paypal, Mastercard, VMware, AT&T, and more. NATS.io has some very impressive technology – check it out. I digressed, but back to RDAF – this data fabric, along with the scheduler, API gateway, and other key components form our control plane. You can separate the control plane and data plane, the way you like, and this is helping us implement many interesting hybrid scenarios.
The platform supports processing of the following types of Data via Data Integrations:
- Datasets: typically finite data, point in time. Examples: asset inventory, configurations etc.
- Data Streams: real-time, continuously generated data. captured in a data lake. Ex: logs, alerts/events
- Persistent Streams: streaming data with persistence and
- Dependency Mappings: Representation of connected assets using stacks that provide topology and dependency of assets or configuration items.
- Log Archives: UTC timestamped and highly compressed log files stored in any MinIO compatible object storage (ex: AWS S3, Azure blob storage, Google cloud storage, etc.)
Visit this link to learn more about these data types
Data Integration Scenarios:
Now that we have some basic understanding of RDAF and key terms let’s discuss a few scenarios. Note that, in all these scenarios all the pipelines are completely field-customizable.
1. Featured Integrations
RDAF provides out-of-the-box integrations for many featured tools like AppDynamics, ServiceNow, Splunk, AWS CloudWatch, Datadog, Dynatrace, etc. We have out-of-the-box packaged pipelines that you can use to integrate and ingest observability data (metrics, events, logs, traces -MELT data). Check out our currently supported featured integrations
2. Custom integrations
If your tool is not a listed integration for us, even then we can easily integrate with your tool using one of the following approaches, which in most cases your tool will support one or more of the following programmatic approaches of providing data to 3rd party tools.
A) REST APIs
If your tool supports HTTP/REST APIs, we have readily available bots that you can use for data integration
B) Graph QL queries
If your tool supports graph-based queries, we also have readily available bots that you can use for data integration
C) Webhook and More
You can receive alerts/events/logs via Webhook using our stream processing bots. You can easily create new webhook endpoints and configure your monitoring tools to send alerts/events to webhook. We also support remote webhooks i.e webhooks that are hosted in your corporate network – this can be achieved using our Event Gateway module, which is a special-purpose containerized module that can help you open many endpoints (like webhook, tcp, udp, syslog, rsyslog, tcpjson etc.) so that you don’t have to open up your firewall ports to stream out data like logs/events.

D) Message Bus integration – Kafka, NATS, AWS Kinesis, MQTT etc.
It is not uncommon to see message-based data ingestion in very large environments, particularly in the financial sector, where high-speed telemetry data is delivered via message bus technologies like Kafka. Following bots and extensions can be used for data integration with messaging systems:
3. Custom integrations – New bot development
If your monitoring tool or in-house solution doesn’t fall into any of the above scenarios, and if you would like to develop a specific extension and bots for your tool, then this would be the scenario. In this case, we provide Bot Development SDK in Python, using which you can develop bots quickly. You can also work with the CloudFabrix presales team or with one of our implementation partners to have the bots developed for you. We have seen new bots being developed anywhere from 3-days to a week. Here are the resources for new bot development:
Using the RDAF platform, customers can cut down complex data integration tasks from months to days, and from hours to minutes, without really undergoing project delays and budget overruns.
Get Started Now, For Free
Simply signup for a free account on cfxCloud – our fully managed cloud-based SaaS offering. Here you have access to a library of 1000+ bots, a self-service low-code studio, a no-code drag & drop pipeline designer, and cfxEdge to ingest/integrate data from on-prem or remote/satellite environments.